
Fable 5 是什么:Anthropic 的 Mythos 级模型首次公开
你把一个跨十几个文件的重构任务丢给 Claude,喝杯咖啡回来发现它已经把上下游依赖全部改完、测试跑绿。2026 年 6 月 9 日发布的 Claude Fable 5 就是冲着这种体验来的。Anthropic 内部一直在训练一类叫 Mythos 的模型,能力远超公开产品线,但安全风险太高一直没放出来。Fable 5 是第一个经过安全处理后面向所有人开放的 Mythos 级模型。
Fable 5 是 Fable 系列的旗舰,定位高于 Opus 级别,能力超过 Anthropic 此前所有公开发布的模型,在几乎所有基准上达到最先进水平,覆盖软件工程、知识工作、视觉理解和科学研究四个大方向。知识截止 2026 年 1 月。
Fable 5 最值得关注的一个特性:任务越长越复杂,它相对其他模型的领先幅度越大。简单问答?和 Opus 4.8 差距不显眼。但一旦任务涉及长上下文推理、多步骤规划、持续几小时的自主工作,差距就拉开了。Fable 5 的核心价值在于"能扛住更大的活",可以自主工作更长时间而不丢失上下文、不偏离目标。
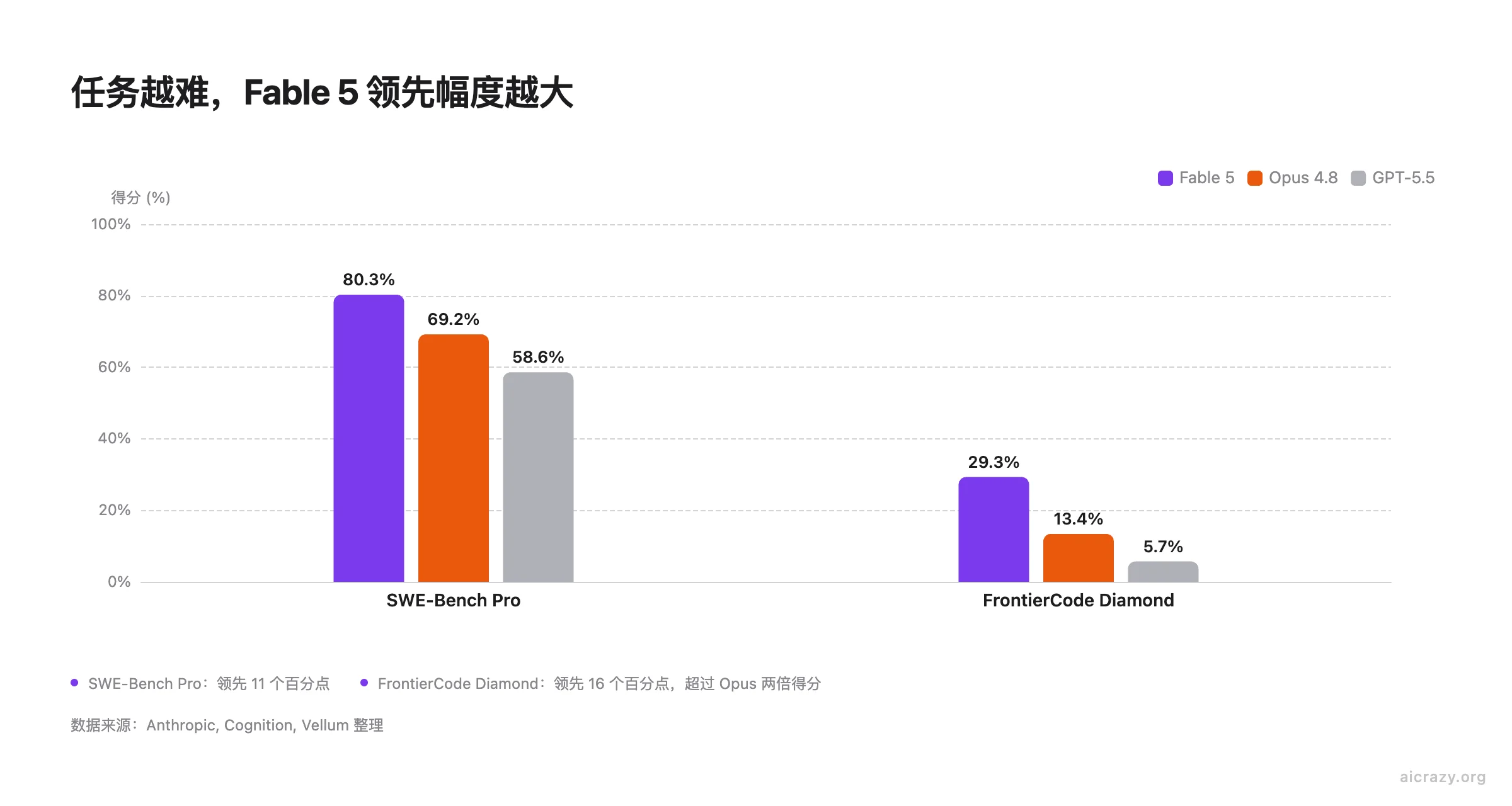
看数据。SWE-Bench Pro(衡量真实 GitHub issue 解决能力)上,Fable 5 得分 80.3%,Opus 4.8 为 69.2%,差距约 11 个百分点。难度再上一档呢?据第三方整理的 Cognition FrontierCode Diamond 子集数据,这个子集只保留最难的生产级编码问题,Fable 5 得分 29.3%,Opus 4.8 骤降至 13.4%,GPT-5.5 低到 5.7%。从 SWE-Bench Pro 的 11 个百分点差距到 FrontierCode Diamond 的 16 个百分点差距(相对 Opus 4.8 超过两倍的得分),任务复杂度每上一个台阶,Fable 5 的领先幅度就进一步放大。简单任务"好一点"。复杂任务变成"能做与做不了"。
参数量未公布。Simon Willison 根据响应速度、定价和知识密度推测它可能是目前所有厂商中参数量最大的模型。外部推测,不是官方确认,但使用体验上 Fable 5 确实呈现出大模型特有的"慢而深"的特征。
Fable 5 和 Mythos 5 的关系:同一个模型,两套访问规则
底层是同一个模型。区别只在分类器的开关状态:Fable 5 面向所有用户,分类器全部启用;Mythos 5 解除了部分安全限制,据 Anthropic 称其拥有全球最强的网络安全能力,API 模型 ID 为 claude-mythos-5。
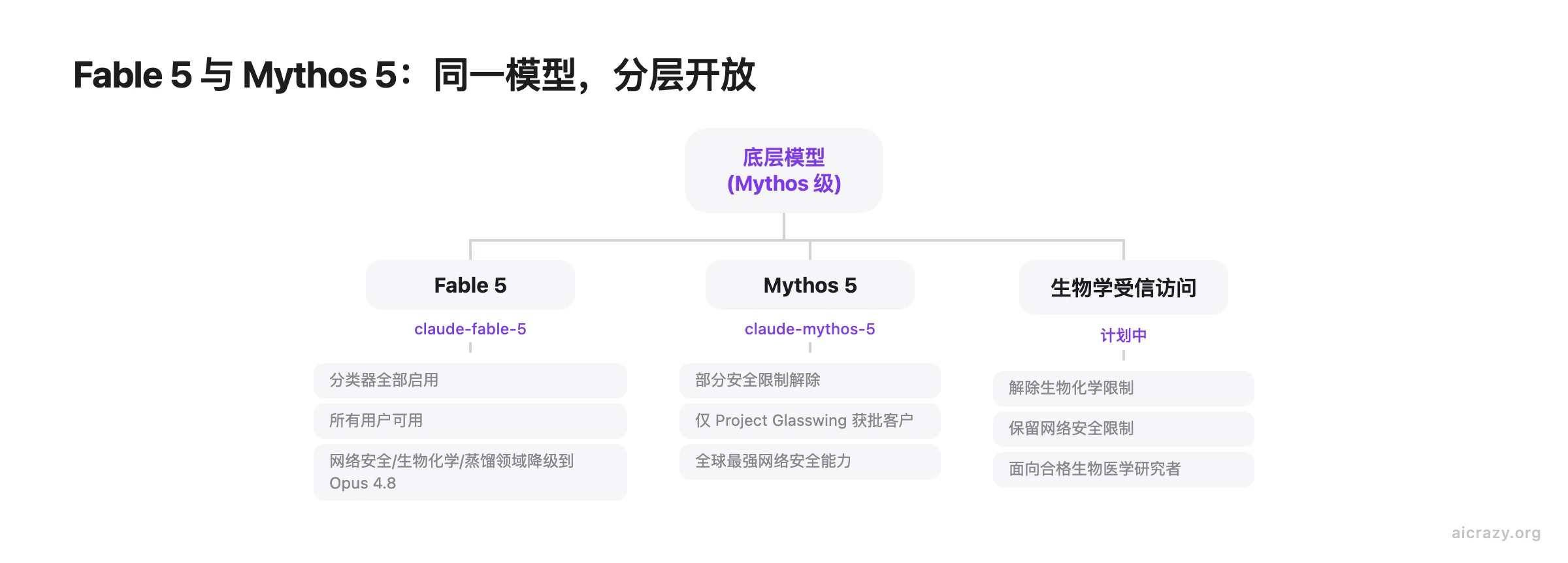
普通开发者用不了 Mythos 5。它仅通过 Project Glasswing(Anthropic 与美国政府的合作项目)向获批客户提供有限访问,Mythos 5 作为此前 Claude Mythos Preview 的升级版本在该框架下部署。普通用户的请求触及网络安全、生物化学或模型蒸馏领域时,Fable 5 会自动降级到 Opus 4.8 处理;Glasswing 的受信合作伙伴则可以直接使用解除了对应限制的 Mythos 5。
受信访问范围在逐步扩大。一个已公布的方向是生物学受信访问计划:符合条件的生物医学研究者将获取解除了生物和化学安全限制的 Fable 5 访问权限,网络安全限制仍然保留。同一个模型,按风险等级分层开放。
Fable 5 的核心能力:编程、视觉、科研实测数据
Stripe 把一个 5000 万行的 Ruby 代码库交给 Claude Fable 5 做整库级迁移。一天跑完,原本需要一整支团队花两个多月。
软件工程是 Fable 5 领先幅度最大的方向。 Cognition 的 FrontierCode 评估显示,Fable 5 即使在中等努力级别下得分就已超过所有前沿模型。Cursor 说得更直接:它是 CursorBench 上的最先进模型,"打开了一类早期模型无法处理的长期问题"。GitHub 的早期测试结论类似,在复杂的长周期编码任务中 Fable 5 展现出超过此前基准的自主性和可靠性。

Simon Willison 的实测更具体。他用 Fable 5 一天之内完成了 Datasette Agent 的 human-in-the-loop 功能,同时向底层 LLM 库提交了 4 个 PR(LLM 0.32a3),几乎全部代码由模型编写。另一个测试里 Fable 5 在 Claude.ai 容器环境中根据简短提示自主完成了 micropython-wasm 向 CPython/WebAssembly 的升级,生成了一个 13.9 MB 的可用 wheel 包。他的总结:这东西像一头巨兽,慢、贵,但能愉快地处理你抛给它的所有任务。
领域知识场景也一样。
金融与分析场景
Hebbia 的金融基准测试(高级推理级别)中,Fable 5 拿到所有模型最高分,文档推理、图表解读和问题求解方面都有明显提升。IMC 的反馈类似:Fable 5 在其交易分析评估中几乎全面通过,覆盖事实查询、概念推理、根因分析和期望值分析。更有说服力的是一家客户的核心分析基准数据,Fable 5 是首个突破 90% 的模型,比 Opus 高 10 个百分点。
日常知识工作也有提升。电子表格场景中 Fable 5 在每个努力级别都超过 Opus 4.8,完成速度快 25%--30%。前沿物理研究中某客户评价 Fable 5 仅用三分之一的推理 token,36 小时内几乎达到了 GPT-5.5 四天才达到的水平。token 效率整体高于 Opus 4.8。
视觉与长上下文记忆
自主工作时间越长,对视觉和上下文记忆的要求越高。Fable 5 两项都有大幅提升。
能从科学图表中提取精确数字,能仅凭截图重建 Web 应用的源代码。举个例子:早期 Claude 模型即使配备复杂辅助工具也难以通关 Pokemon FireRed,Fable 5 用纯视觉方式(无地图、无导航工具)就打通了全程。
长上下文记忆同样突出。Slay the Spire 游戏测试中,给 Fable 5 提供持久文件记忆后,性能提升幅度是 Opus 4.8 的三倍,进入最终章的频率也是三倍。Fable 5 可以自主工作的时间比此前任何 Claude 模型都更长,在需要持续推理的长任务中不会像前代模型那样在中途"忘掉"关键信息。
Mythos 5 在药物设计和基因组学等科研场景也展现了强大能力,但这些功能目前仅通过受信访问计划开放。
Fable 5 定价与模型对比:比 Opus 贵一倍,比 Mythos Preview 便宜过半
截至 2026 年 6 月,Fable 5 的 API 定价为每百万输入 token 10 美元、每百万输出 token 50 美元。Opus 4.5--4.8 的两倍,不到此前 Mythos Preview 价格的一半。长上下文调用不额外加价,200K 还是 100 万 token 的上下文窗口,单价一样。
| 模型 | 输入价格(每百万 token) | 输出价格(每百万 token) |
|---|---|---|
| Claude Opus 4.5,4.8 | $5 | $25 |
| Claude Fable 5 | $10 | $50 |
| Claude Mythos Preview | >$20 | >$100 |
从 Opus 升级到 Fable 5,账单翻倍。据 Simon Willison 实测,高强度使用场景下(如连续多小时的代码生成任务)这个价差会快速累积。但 Fable 5 在复杂任务上的完成速度和质量提升往往能抵消价格增长,Stripe 用它一天完成团队两个月的迁移工作量,单次任务的总成本反而可能更低。
价格翻倍不等于成本翻倍。 Fable 5 完成同样任务消耗的 token 更少。电子表格任务完成速度快 25%--30%,相同输出下用的轮次更少;前沿物理研究中 Fable 5 只用了 GPT-5.5 三分之一的推理 token 就接近同等结果;据第三方整理的数据,在 FrontierCode 这类硬编码基准上,多数模型需要 max effort 才能拿到高分,Fable 5 在 medium effort 就领先,省下的推理 token 直接折算成费用差。复杂多步骤任务上,Fable 5 的实际成本增幅通常远低于账面的 2 倍。具体节省比例取决于任务类型和 effort 级别,没有一个普适数字,但在电子表格、物理研究、编码基准三个独立场景中 Fable 5 均以更少 token 达到同等或更好结果。简单查询?Opus 甚至 Sonnet 更经济。Fable 5 的性价比优势集中在"任务越长越复杂、领先越大"的场景。
怎么获取 Fable 5:平台、订阅计划与免费期
Fable 5 的 API 模型 ID 是 claude-fable-5(截至 2026 年 6 月),可以在以下平台调用:
- Claude API,直接通过 Anthropic 官方接口
- AWS Bedrock / Claude Platform on AWS
- Google Vertex AI
- Microsoft Foundry
产品端全线上线:Claude.ai 聊天界面、Claude Code CLI、Claude Code for web、Claude Cowork。
订阅用户的免费窗口:6 月 9 日发布当天起至 6 月 22 日,Pro、Max、Team 和按席位计费的 Enterprise 用户可以免费使用 Fable 5。6 月 23 日起从订阅计划中移除,改为消耗 Usage Credits(容量允许的话免费期可能延长)。Usage Credits 在 Settings > Usage 中启用,按 API 价格结算,每日上限 $2000。
恢复时间表?没有。Anthropic 说容量允许时会尽快恢复。
在 Claude Code 中使用 Fable 5:版本要求与切换方法
先确认版本。Fable 5 需要较新版本的 Claude Code,旧版本的模型选择器里看不到 Fable 5。升级一条命令:
claude update
四种方式切换。
会话内直接切换最常用,随时在对话中输入 /model fable 即可(也接受完整模型名 /model claude-fable-5)。临时试用或者在 Opus 和 Fable 之间来回切换,用这个最方便。
/model fable
启动时指定模型,适合想直接进入 Fable 5 会话的场景:
claude --model fable
剩下两种方式适合不想每次手动指定的情况。环境变量 export ANTHROPIC_MODEL=claude-fable-5 适合在 CI/CD 或脚本中固定使用。配置文件则是永久方案,编辑 ~/.claude/ 目录下的用户配置文件,将 model 字段设为 claude-fable-5,之后每次启动都默认 Fable 5。
有一个硬限制:启用了零数据留存(ZDR)的账户无法使用 Fable 5。在 ZDR 模式下,模型选择器会隐藏或禁用 Fable 5 选项。组织开启了 ZDR 的话,联系管理员确认策略。
安全分类器与 API 适配:拒绝、降级和迁移注意事项
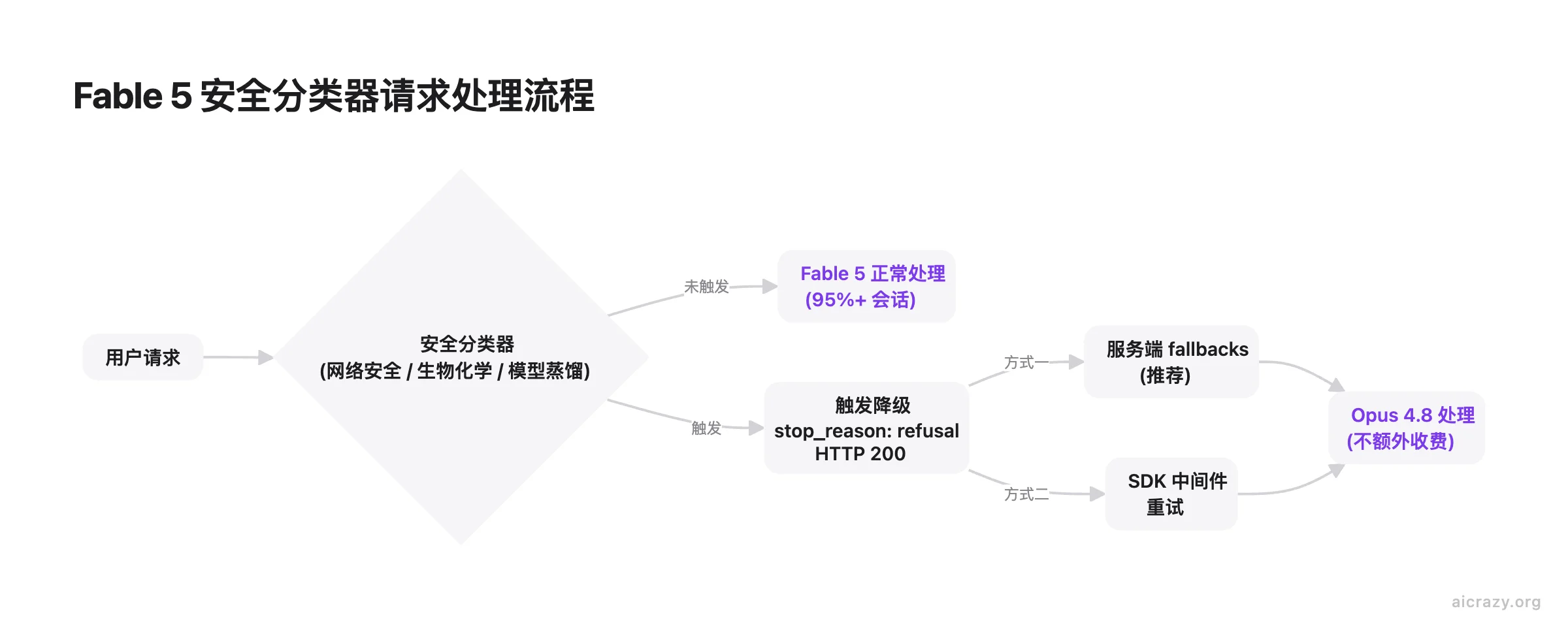
Fable 5 的分类器覆盖三个领域:网络安全、生物与化学、模型蒸馏。触及这三个领域时,分类器不会直接拒绝请求,而是自动降级到 Opus 4.8 处理。超过 95% 的会话不触发任何降级。
分类器做了保守调优,部分无害请求也会误拦,比如安全审计教程、化学实验流程的讨论。Anthropic 在逐步减少误报率。外部合作伙伴的测试结果显示 Fable 5 的分类器是所有测试模型中最强的(包括 Opus 4.8 和 Opus 4.7),对网络攻击规划、漏洞利用开发(exploit development)和防御规避三类有害请求的合规率为零,超过 1000 小时的外部漏洞赏金测试也未发现通用越狱方法。对齐评估方面,Fable 5 的未对齐行为(包括欺骗和配合滥用)处于低水平,与 Opus 4.8 相近。
另一个限制:30 天数据留存,所有流量,不支持零数据留存(ZDR)。数据合规要求严格的企业需要评估。
API 中的拒绝(refusal)机制
拒绝处理和传统模型有本质区别。分类器触发后 Messages API 返回 stop_reason: "refusal",但 HTTP 状态码是 200,不是 4xx。你现有的错误处理逻辑不会捕获它,拒绝会被当成正常响应静默通过。
处理降级重试有三种方式:
- 服务端
fallbacks参数(推荐):在请求中传入fallbacks参数,API 自动将被拒绝的请求重试到指定的降级模型。目前在 Claude API 和 AWS 平台处于 Beta 阶段。 - SDK 客户端中间件:用 SDK 内置的中间件从客户端发起重试,支持 TypeScript、Python、Go、Java、C# 五种语言,不受平台限制。
- 手动实现:自己写重试逻辑,检查
stop_reason字段后切换模型重发。任何语言和平台都能做,但维护成本最高。
被拒绝的请求没产生输出就不收费。fallbacks 重试时降级积分会退还提示词缓存费用,不二次收取。
思维链和自适应思考的变化
自适应思考默认开启,不可关闭。 thinking: {"type": "disabled"} 不再支持,用 effort 参数控制思考深度。
原始思维链永不返回,这对现有代码影响较大。thinking.display 参数控制思维块内容,可选 summarized(可读摘要)或 omitted(默认,空的 thinking 字段)。应用如果依赖解析原始思维链做后处理,迁移到 Fable 5 后需要改造。
支持的功能与迁移
截至 2026 年 6 月,Fable 5 支持的 API 功能包括:Effort 参数、Task Budgets(Beta)、Memory 工具、代码执行、Programmatic tool calling、Context editing(Beta)、Compaction、Vision。
从 Opus 4.8 或 Mythos Preview 迁移过来,改动集中在三处:检查 stop_reason: "refusal" 的新响应格式、接入降级重试逻辑、适配不可关闭的自适应思考。官方迁移指南有具体步骤。
Fable 5 实际使用成本:effort 级别与消耗控制
Simon Willison 实测数据:Fable 5 发布当天(2026 年 6 月 9 日),他消耗了 $110.42 的 token,全部走 $100/月的 Max 订阅计划。费用高度集中,Datasette Agent 一个项目就占了 $99.26(89.9%),吃掉 7820 万 token。普通对话不太花钱,成本压力来自长时间自主编码任务。
订阅计划中 Fable 5 的额度消耗约为 Opus 的 2 倍。你习惯让 Opus 跑完一整天的任务?换 Fable 5 大概半天就到限额了。
effort 级别直接决定单次请求的费用跨度。 Simon Willison 用 SVG 生成任务测试了五个级别(截至 2026 年 6 月数据):
| effort | 输出 token | 单次费用 |
|---|---|---|
| low | 1,929 | ~9.67¢ |
| medium | 2,290 | ~11.48¢ |
| high | 2,057 | ~10.31¢ |
| xhigh | 5,992 | ~29.99¢ |
| max | 14,430 | ~72.18¢ |
low 到 max 费用差距接近 7.5 倍,选错级别意味着白花钱或白等时间。Anthropic 官方文档的选择原则是"按任务难度匹配 effort,而非一律拉满"。按典型开发任务整理的粗略对应关系:
- low:适合简单分类、快速查找、高频低复杂度的批量调用,类似"判断这段文本属于哪个类别"的场景,追求速度和成本
- medium:日常代码补全、单函数生成、单文件 bug 修复、工具调用密集的常规工作流,官方建议 medium 作为多数场景的起点
- high(API 默认值):单文件重构、中等规模的代码审查、需要一定推理深度但范围可控的分析任务
- xhigh:跨文件重构、复杂代理工作流、长上下文代码生成,官方建议编码和代理场景从 xhigh 起步
- max:仅在 xhigh 效果不够、评估数据显示仍有提升空间时使用,适合最高难度的推理和分析任务
实用判断:你自己几分钟能给出答案的任务,low 或 medium 足够;你自己需要几小时甚至几天才能搞定的,xhigh 或 max 才值得。effort 拉太高不仅浪费 token,还可能让模型过度推理引入不必要的复杂度。
免费窗口 6 月 23 日关闭后,Usage Credits 按 API 同价结算,每日上限 $2,000。Settings > Usage 里启用充值即可。
常见问题
Fable 5 和 GPT-5.5 谁更强,价格差多少?
截至 2026 年 6 月,SWE-Bench Pro 上 Fable 5 得分 80.3%,GPT-5.5 为 58.6%,Opus 4.8 为 69.2%;Intelligence Index 上 Fable 5 得分 65,GPT-5.5 为 60,Gemini 3.1 Pro 为 57。Fable 5 在基准上领先明显。价格上 GPT-5.5 的 API 为每百万输入 token $5、输出 $30(200K 上下文以内),Fable 5 是两倍(输入 $10、输出 $50)。简单问答两者差距不大,越复杂 Fable 5 优势越明显。
Fable 5 的分类器误报会影响正常使用吗?
绝大多数场景不会。95% 以上的会话不触发降级。如果你的业务涉及网络安全或生物化学讨论,可能偶尔遇到误报降级到 Opus 4.8,接入 fallbacks 参数或 SDK 中间件可以让降级对用户无感知。详见上文"安全分类器"章节。
Fable 5 的响应速度比 Opus 4.8 慢多少?
慢很多。设计取舍,不是性能问题。据 Artificial Analysis 的数据,Fable 5 通过 Anthropic API 的首 token 延迟(TTFT)约 108 秒,Azure 渠道约 86 秒,Opus 4.8 通常几秒内就出首 token。单次响应上,Opus 4.8 处理一个编码任务通常 3--15 秒返回,Fable 5 同类任务可能需要 60 秒到数分钟;多步骤自主工作场景下累计耗时视步骤数而定,可能远长于此。它在回复前会进行深度推理链、调用工具、自检输出,慢是这套工作模式的必然结果。需要实时交互?Opus 4.8 或 Sonnet 更合适。
Fable 5 从订阅计划移除后,怎么跟进恢复进度?
不用等恢复。6 月 23 日之后在 Settings > Usage 中启用 Usage Credits 充值就行,按 API 同价结算。至于什么时候重新纳入订阅计划,Anthropic 说会提前通知但没给日期。跟进渠道:Anthropic 官方博客发重大产品变更,API 文档的模型介绍页更新技术细节和可用性状态。
分类器降级到 Opus 4.8 后,输出质量会受影响吗?
会。降级后就是 Opus 4.8 在处理,复杂推理和长上下文任务上能力下降可以感知到。但过程透明:系统通知你发生了降级,API 层返回 stop_reason: "refusal",不会静默替换。Opus 4.8 仍然是 Claude 家族第二强的模型,绝大多数非敏感领域的任务用它足够。经常触发?接入 fallbacks 参数让切换自动化。
Fable 5 强制 30 天数据留存,其他前沿模型的数据留存政策怎么比?
Fable 5 对所有 API 流量强制 30 天数据留存,不支持零数据留存。硬限制。OpenAI 的 GPT-5.5 默认也是 30 天留存用于滥用监控,但企业客户可以申请开启零数据留存(ZDR),审批通过后提示词和输出不被存储,走欧盟节点的请求则默认零留存。Google 的 Gemini 3.1 Pro 在 Vertex AI 上支持通过合同修订实现零数据留存,Gemini API 也提供了 ZDR 选项。截至 2026 年 6 月,GPT-5.5 和 Gemini 3.1 Pro 都为企业客户提供了零数据留存的申请通道,Fable 5 没有。数据合规要求严格的企业需要评估这个限制。