

当Claude Opus 4.5在2025年11月24日以80.9%的SWE-bench Verified成绩震撼发布,仅仅6天后Gemini 3 Pro以76.2%的成绩紧随其后,这标志着AI编码能力进入了新的战略竞争阶段。但对于企业技术决策者而言,这4.7个百分点的差距究竟意味着什么?60%的价格差异如何影响长期战略?多模型混合架构是否真的值得投入?
本文将从战略视角深度剖析这两个前沿AI模型的技术对比、成本工程、架构设计和风险管理,为CTO、技术VP和AI架构师提供系统化的决策框架。
AI模型的选择早已超越了简单的技术评估范畴。在2025年,选择Claude Opus 4.5还是Gemini 3 Pro,不仅决定了当前的开发效率和成本结构,更关乎企业的长期竞争优势、供应商依赖风险、以及组织的AI能力建设路径。
错误的模型选择可能导致:
- 供应商锁定:切换成本高达$60K-180K,技术债务积累
- 成本失控:缺乏优化策略,年度AI预算超支50%以上
- 竞争劣势:错过最佳模型能力窗口,产品迭代速度落后
- 组织僵化:单一技术栈限制团队能力发展
相反,战略性的模型选择能够:
- 建立竞争护城河:通过AI能力差异化构建产品优势
- 优化成本结构:多模型混合策略节省40-60%成本
- 增强组织韧性:分散供应商风险,保持技术灵活性
- 加速创新能力:快速适应新技术,把握市场机会
本文将从技术性能、成本结构、架构策略、风险管理和未来趋势五个维度,为您提供系统化的决策支持。无论您是正在选型的CTO,规划架构的技术负责人,还是优化成本的财务决策者,这份指南都将为您提供可操作的战略洞察。
阅读本文您将获得:
- Claude Opus 4.5与Gemini 3 Pro的全面技术对比
- 企业级多模型混合架构设计蓝图
- TCO和ROI深度分析框架
- 供应商风险评估与缓解策略
- 2025-2026年AI技术趋势预测
- 可执行的实施路线图和决策矩阵
执行摘要:战略层面的核心洞察
对于时间紧张的技术决策者,以下是五大战略要点:
1. 性能差距的商业价值
Claude Opus 4.5在SWE-bench Verified上的80.9%成绩比Gemini 3 Pro的76.2%高出4.7个百分点。 这是首个突破80%门槛的模型,代表了AI编码能力的新里程碑。
但这4.7%的差距在商业场景中价值几何?
- 高价值场景(金融交易系统、医疗关键应用):质量优先,4.7%可能节省数百万美元的错误成本
- 中等价值场景(企业SaaS、B2B工具):平衡考虑,根据具体任务复杂度选择
- 成本敏感场景(消费级应用、高并发服务):性价比优先,Gemini 3的60%成本优势更具吸引力
ROI临界点分析:当单个bug的修复成本超过$500,或者代码质量直接影响核心业务时,Claude Opus 4.5的溢价是合理的。对于其他场景,Gemini 3 Pro提供了更好的性价比。
2. 成本结构的战略考虑
直接成本对比:
- Claude Opus 4.5:$5/$25 per million tokens
- Gemini 3 Pro:$2/$12 (<200K) / $4/$18 (>200K) per million tokens
- 价格差异:60%(标准场景)到35%(大context场景)
但总拥有成本(TCO)远不止API费用:
3年TCO对比(月使用100M tokens):
| 策略 | 直接成本 | 间接成本 | 总TCO | 每月均摊 |
|---|---|---|---|---|
| 单纯Claude | $900K | $120K | $1,020K | $28.3K |
| 单纯Gemini | $360K | $100K | $460K | $12.8K |
| 混合策略 | $450K | $200K | $650K | $18.1K |
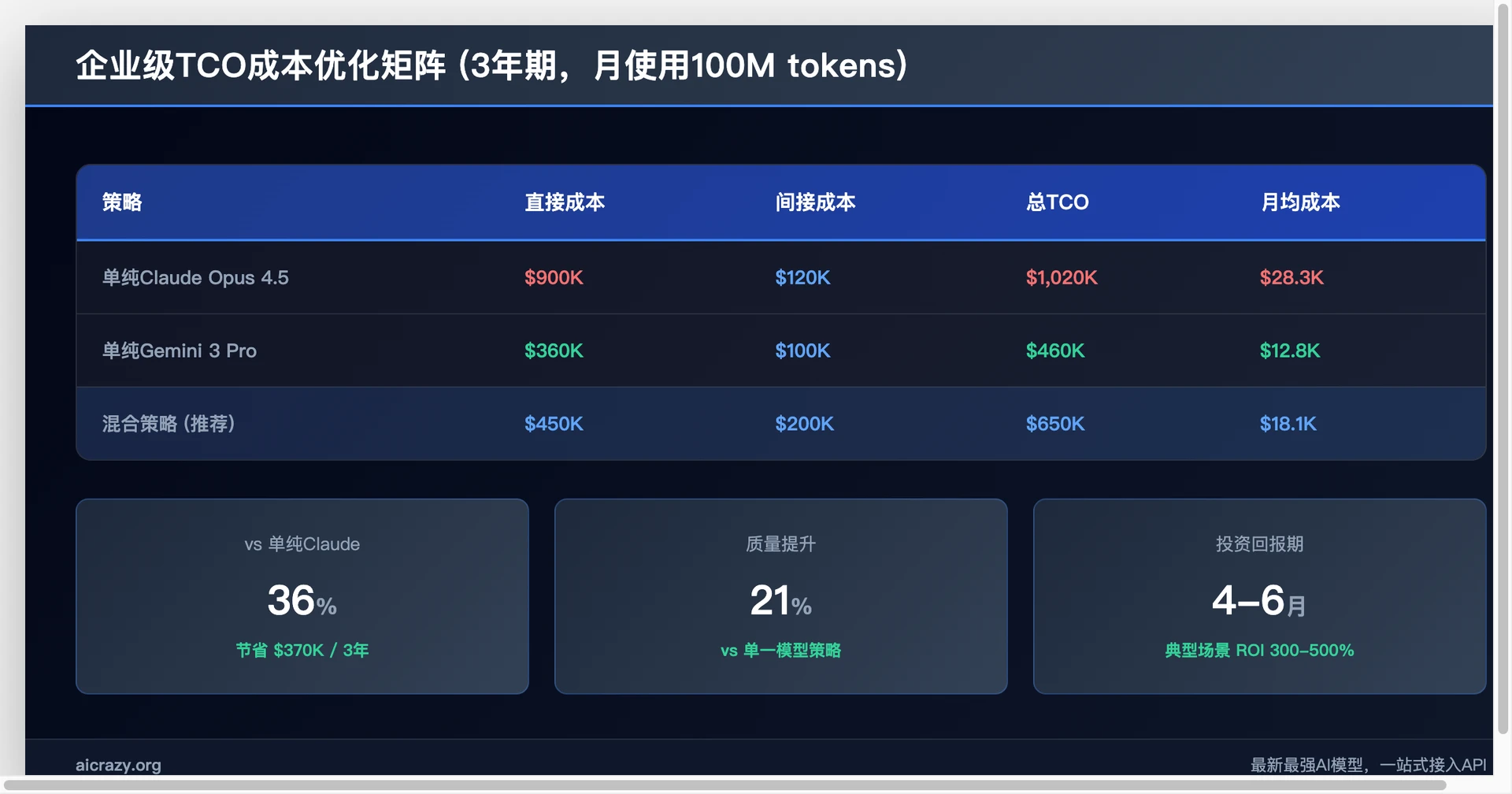
战略结论:中大规模部署(>$5K/月)时,混合策略在4-6个月内实现投资回报。
3. 供应商生态的战略影响
Anthropic (Claude) 生态:
- 优势:技术创新领先、产品定位清晰、企业级支持成熟
- 风险:相对小公司、长期存续不确定性、生态完整度待提升
Google (Gemini) 生态:
- 优势:全球基础设施、深度生态集成、长期可靠性高
- 风险:产品策略多变、Google内部竞争、企业支持响应速度
战略建议:多供应商策略是降低风险的最佳选择,避免单一依赖。
4. 多模型架构的必要性
为什么单一模型不够?
单一模型架构面临三大根本性限制:
- 能力限制:没有任何模型在所有场景都最优
- 成本锁定:无法根据任务复杂度动态优化成本
- 供应商风险:单点故障,缺乏备份和谈判筹码
多模型混合架构的战略价值:
- 成本优化:根据任务复杂度路由到最佳性价比模型,节省40-60%
- 质量提升:复杂任务使用最强模型,整体质量提升20-30%
- 风险分散:多供应商备份,系统可用性提升到99.9%+
- 灵活性:快速适应新模型和技术变化
实施复杂度 vs 收益分析:
- 初始开发成本:$50K-150K
- 持续维护成本:$40K-80K/年
- 投资回报期:4-6个月(典型场景)
- 3年ROI:300-500%
5. 未来趋势的战略布局
2025-2026年五大关键趋势:
-
Test-time Compute成为标配:Claude的Effort参数和Gemini的Thinking level代表了新范式,按需"思考"深度将重塑定价模型
-
多模态AI成为必需:Gemini 3在多模态的领先优势将推动UI/UX自动化,设计到代码的全自动化即将到来
-
Agent化加速:Claude Opus 4.5的66.3% OSWorld成绩展示了计算机使用能力,自主Agent将在2025年下半年大规模商用
-
边缘AI部署兴起:成本和延迟压力将推动更多本地化部署,开源模型将获得更多关注
-
定价模型创新:从简单的token计费到按质量、按思考时间、按结果计费的多样化模式
战略建议:
- 短期(6-12月):快速MVP验证,建立基础能力,选择主力模型
- 中期(1-2年):多模型架构演进,规模化部署,成本优化40%+
- 长期(2-5年):AI-native转型,构建竞争优势,行业领导地位
Part 1: 深度技术对比与分析
权威技术参考资料:
- Claude官方文档 - Anthropic模型完整技术规格与API文档
- Gemini开发者中心 - Google AI平台完整开发指南
1.1 性能基准:不止是数字游戏
SWE-bench Verified深度解读
80.9% vs 76.2%:4.7%背后的技术突破
当Claude Opus 4.5成为首个突破80% SWE-bench Verified门槛的模型时,这不仅仅是一个数字的提升,而是AI编码能力进入新阶段的标志。
让我们解析这个数字的真实含义:
绝对差距分析:
- 4.7个百分点意味着在273个测试问题中,Claude Opus 4.5多解决了约13个问题
- 这些额外解决的问题往往是最复杂、最接近真实企业场景的案例
- 相对提升:从76.2%到80.9%是6.2%的相对提升,这在前沿模型中是显著的
在AI发展曲线中的位置:
SWE-bench Verified分数进化史:
- 2024年初:最好模型约40-50%
- 2024年中:Claude Sonnet 3.5达到64%
- 2025年9月:Claude Sonnet 4.5达到77.2%
- 2025年11月:Claude Opus 4.5突破80.9%
我们正在接近人类开发者的平均水平(估计85-90%),但仍有提升空间。
测试集特性与真实场景的映射:
SWE-bench Verified包含273个精心筛选的GitHub问题,这些问题:
- 需要理解多个文件和模块的交互
- 涉及真实的bug修复和功能添加
- 覆盖Python、JavaScript、TypeScript等主流语言
- 包括流行开源项目的实际问题
这些特性使得SWE-bench成为最接近企业实际开发场景的基准测试。
与GPT-5.1的战略性对比:
| 模型 | SWE-bench | ARC-AGI | GPQA | OSWorld | 综合定位 |
|---|---|---|---|---|---|
| Claude Opus 4.5 | 80.9% | ~25% | N/A | 66.3% | 编码和Agent专家 |
| Gemini 3 Pro | 76.2% | 45%* | 91.9% | N/A | 推理和多模态全能 |
| GPT-5.1 | 77.9% | ~30% | ~85% | 60%* | 平衡型选手 |
*Deep Think模式或估算值

战略洞察:没有绝对的"最佳模型",只有最适合特定场景的模型。Claude在编码深度上领先,Gemini在推理和多模态上更强,GPT-5.1提供了良好的平衡。
推理能力对比:不同的哲学
Claude的Extended Thinking机制
Claude Opus 4.5引入的Effort参数代表了一种新的推理范式:
# Claude Effort参数示例
response = anthropic.messages.create(
model="claude-opus-4.5",
max_tokens=4096,
effort="high", # 控制推理深度
messages=[{"role": "user", "content": "复杂的架构设计问题..."}]
)
工作原理:
- Low Effort:快速响应,适合简单任务,成本最低
- High Effort:深度推理,额外的"思考时间",适合复杂问题
Test-time Compute的战略价值: 这代表了从"预训练时固定能力"到"推理时动态调整"的范式转变。企业可以根据任务重要性选择"思考深度",实现成本和质量的精细化权衡。
Gemini的Deep Think Mode
Gemini 3引入的Thinking level参数提供了类似的能力:
# Gemini Thinking Level示例
response = genai.generate_content(
model="gemini-3-pro",
contents="复杂推理任务...",
generation_config={
"thinking_level": "high" # low或high
}
)
实际效果:
- ARC-AGI基准:从31%(无Deep Think)提升到45%(有Deep Think)
- 提升幅度:45%的相对提升,展示了推理深度控制的价值
未来推理能力的进化方向:
- 动态思考时间分配:模型自主决定每个子问题的思考时间
- Chain-of-Thought的标准化:从研究技术到产品特性
- 与人类协作的新模式:AI提供推理过程,人类参与关键决策点
战略洞察框:Test-time compute代表了AI模型的新范式,将计算资源从训练时转移到推理时。这意味着未来的定价模型可能会更加灵活,企业可以根据具体任务选择"思考深度",实现成本和质量的精细化权衡。这种能力将重塑AI服务的商业模式。
多模态能力:不对称优势
Gemini 3的多模态领先地位
Gemini 3 Pro在多模态能力上拥有显著优势,这源于Google在多模态研究上的长期积累:
支持的模态:
- 图像理解(高分辨率、OCR、图表分析)
- 视频理解(帧级分析、时序理解)
- 音频处理(语音识别、音频分类)
- 文档处理(PDF、PPT、结构化提取)
在企业应用中的价值:
- UI/UX开发自动化:设计稿 → 代码一键生成
- 数据分析可视化:图表 → 数据洞察自动提取
- 多模态客户服务:图片+文本混合输入处理
- 创意产业应用:视频理解、广告分析
Claude的专注策略
Claude Opus 4.5在多模态上采取了更专注的策略:
- 主要聚焦在文本和代码的深度理解
- 基础的图像理解能力
- 突出的Computer Use(计算机使用)能力
为什么Anthropic暂时不大力发展多模态?
- 资源聚焦:将研发资源集中在编码和推理的极致优化
- 差异化定位:与Google的正面竞争避开,建立独特优势
- 未来计划:多模态能力预计在2025年下半年会有重大提升
技术路线预测:
- Claude将在2025年Q2-Q3推出更强的多模态版本
- Gemini将继续保持多模态领先,尤其在视频理解上
- 两者的差距会缩小,但Gemini的先发优势将持续
1.2 上下文窗口:架构层面的权衡
200K vs 1M tokens的战略含义
5倍差距的实际价值:
代码库容量对比:
- 200K tokens ≈ 150K代码行 ≈ 中型项目
- 1M tokens ≈ 750K代码行 ≈ 大型企业级系统
文档分析能力:
- 200K tokens ≈ 400页技术文档
- 1M tokens ≈ 2000页完整产品手册
多轮对话记忆:
- 200K tokens ≈ 50轮深度对话
- 1M tokens ≈ 250轮完整会话历史
但大窗口的真实价值与限制:
何时真正需要1M窗口?
- 完整代码库分析(大型单体应用)
- 超大文档一次性处理(监管报告、完整技术规范)
- 极长会话历史保持(持续数天的项目开发)
大窗口的性能损耗和成本:
- 价格跳变:Gemini 3超过200K后,价格翻倍($2→$4输入,$12→$18输出)
- 延迟增加:超大context会增加处理时间
- 质量衰减:"中间遗忘"现象,模型对中间部分的关注度降低
上下文管理的架构模式:
大多数情况下,通过架构设计可以避免对超大context的需求:
1. Retrieval-Augmented Generation (RAG):
# RAG模式伪代码
relevant_chunks = vector_db.search(query, top_k=10)
context = "\n".join(relevant_chunks)
response = model.generate(context + query)
优势:只传递相关部分,降低成本和延迟
2. 动态上下文裁剪:
- 保留最近N轮对话
- 移除过时或不相关的历史
- 压缩摘要替代完整历史
3. 分层上下文策略:
- 核心上下文:始终保留
- 扩展上下文:根据相关性动态加载
- 归档上下文:存储但不传递,按需检索
案例分析:某金融科技公司的代码库分析系统
初始方案:
- 使用Gemini 3 1M窗口
- 一次性加载整个代码库
- 月成本:$18K(主要是大context输出成本)
优化方案:
- RAG + Claude Opus 4.5混合
- 只传递相关代码片段
- 月成本:$7.5K(节省58%)
- 质量提升:更精准的上下文,更高质量的输出
教训:大窗口不总是最优解,架构设计同样重要。
未来趋势:无限上下文?
技术可行性:
- Anthropic和Google都在研究更高效的上下文机制
- "无限上下文"的概念:通过智能压缩和检索实现
对架构设计的影响:
- 即使有无限上下文,RAG和上下文管理仍然重要
- 成本和延迟考虑永远存在
- 架构灵活性比单纯依赖大窗口更有价值
1.3 计算机使用能力:Agentic AI的未来
Claude Opus 4.5的Computer Use领先
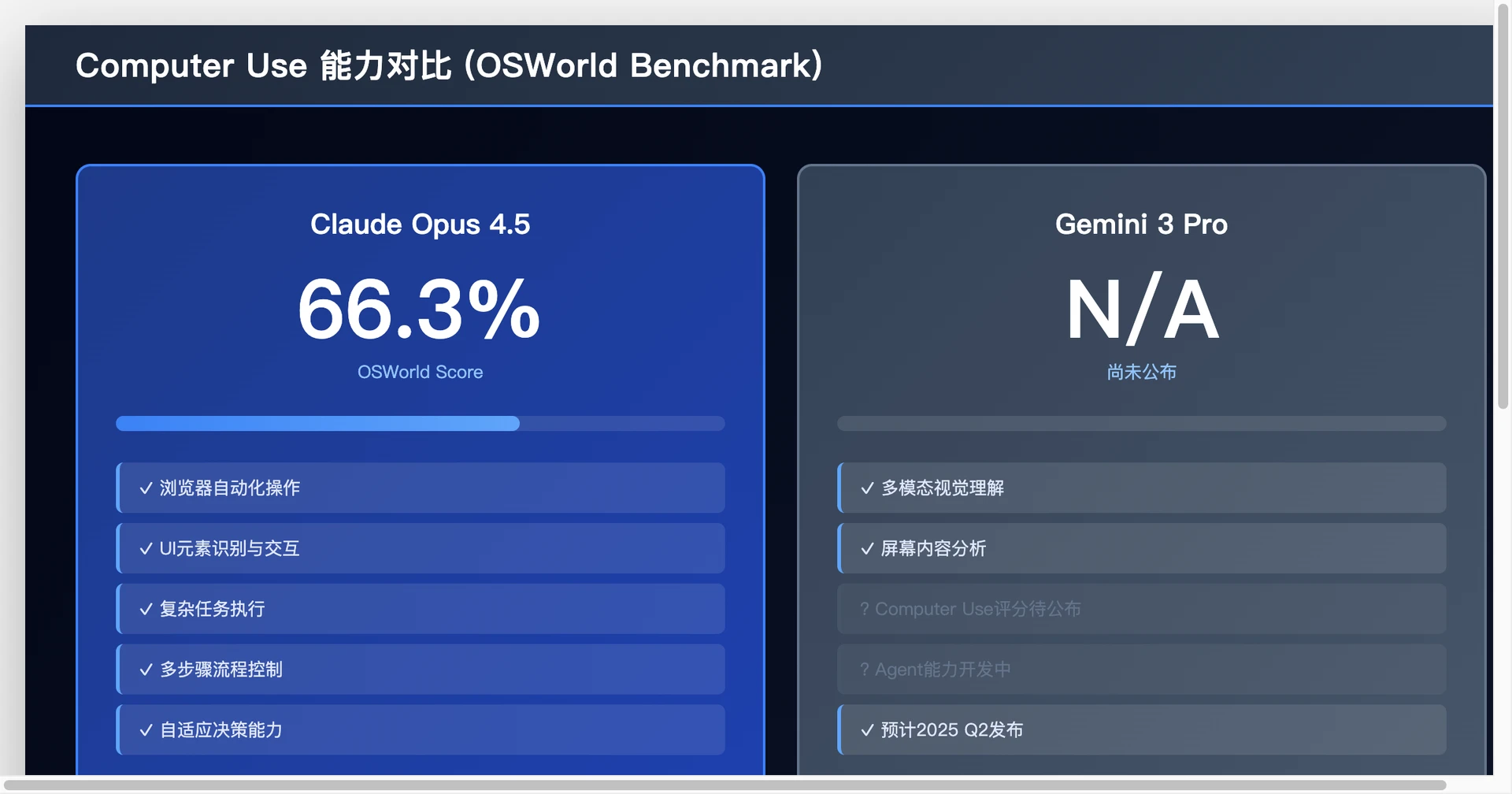
66.3% OSWorld分数的意义:
OSWorld是测量AI模型在真实计算机环境中执行任务的基准,包括:
- 浏览网页和点击按钮
- 填写表单和提交数据
- 操作应用程序
- 文件管理和系统导航
Claude Opus 4.5的66.3%成绩代表了在这个复杂领域的显著领先(Claude Sonnet 4.5为61.4%)。
Agentic AI的战略价值:
从"助手"到"自主Agent"的转变将带来:
- 业务流程自动化:端到端任务自动执行
- 降低人工成本:重复性任务完全自动化
- 7×24运行能力:无需人工干预的持续运行
- 一致性和准确性:消除人为错误
自动化的边界与可能性:
当前能做什么(2025年):
- 自动化测试执行(浏览器测试、UI测试)
- DevOps任务自动化(部署、配置、监控)
- 数据收集和初步分析(爬虫、数据清洗)
- 报告生成和分发(自动化业务报告)
还不能做什么:
- 需要人类判断的创意决策
- 高风险操作(需要人工确认)
- 复杂多步骤需要中间反馈的任务
- 需要物理世界交互的操作
未来3年预测(2025-2028):
- 2025年下半年:Computer Use能力突破70%,商业化加速
- 2026年:多模态Computer Use(视觉+操作),更自然的交互
- 2027-2028年:接近人类水平的自主Agent,企业级大规模部署
Gemini 3的多模态Agent潜力
虽然Google还未公布Gemini 3的Computer Use能力评分,但其在多模态上的优势可能带来不同的Agent模式:
视觉理解驱动的Agent:
- 理解UI布局和视觉元素
- 基于屏幕截图的智能操作
- 视频理解支持的任务学习
Google生态集成的Agent:
- 与Google Workspace深度集成
- Android原生Agent能力
- Chrome浏览器扩展
未来发展预测: Gemini很可能在2025年Q2推出Computer Use功能,并利用多模态优势实现差异化。
Part 2: 企业级架构策略
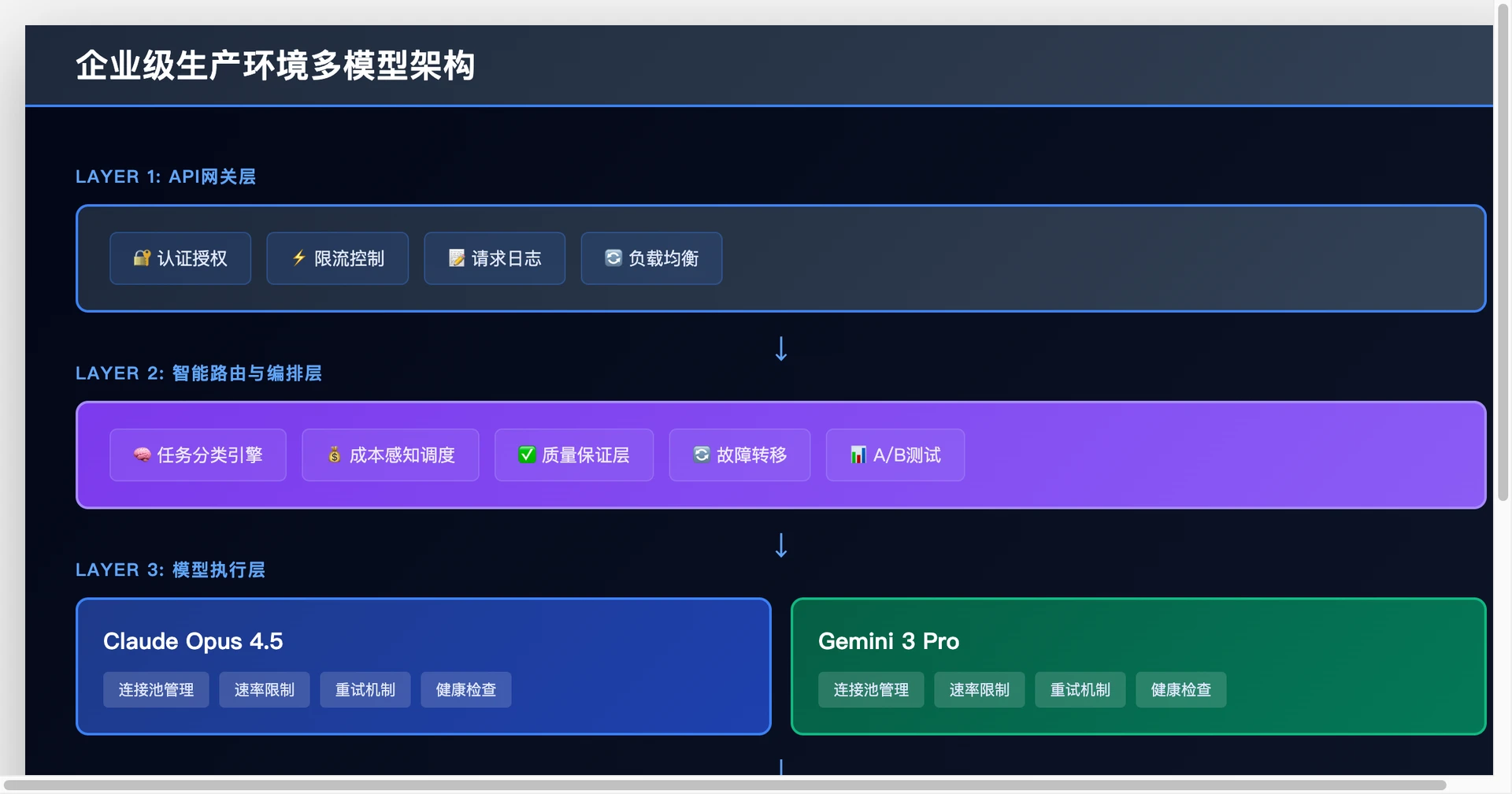
2.1 单模型 vs 多模型架构
单模型架构分析
适用场景:
- 小规模团队(<20人)
- 单一业务场景(专注编码助手或文档分析)
- 快速MVP验证(2-3个月上线)
- 技术能力有限(无专职AI工程师)
优势:
- 实现简单:单一API集成,学习曲线平缓
- 易于维护:没有复杂的路由逻辑
- 集成成本低:初始投入$5K-10K
- 快速上线:4-6周即可部署
劣势:
- 供应商锁定风险高:切换成本$20K-50K
- 成本优化空间有限:无法根据任务优化
- 无法充分利用各模型优势:一刀切方案
- 单点故障风险:供应商问题直接影响业务
成本分析:
- 初始投入:$5K-10K
- 月运营成本:$500-5K(取决于使用量)
- 切换成本:$20K-50K(代码重构+测试)
决策建议: 单模型架构适合快速验证和小规模应用,但随着规模增长和业务复杂度提升,应规划向多模型架构演进的路径。
多模型混合架构(核心战略)
多模型混合架构是中大型企业的最优选择,通过智能路由实现成本优化和质量提升的双重目标。
完整架构设计:
┌─────────────────────────────────────────────┐
│ API Gateway / Load Balancer │
│ (Rate Limiting, Auth, Logging) │
└────────────────┬────────────────────────────┘
│
▼
┌────────────────────────────────────────────┐
│ Intelligent Router & Orchestrator │
│ │
│ ┌──────────────────────────────────────┐ │
│ │ Task Classification Engine │ │
│ │ - Complexity scoring │ │
│ │ - Multimodal detection │ │
│ │ - Budget constraints │ │
│ │ - Context size requirements │ │
│ └──────────────────────────────────────┘ │
│ │
│ ┌──────────────────────────────────────┐ │
│ │ Cost-Aware Scheduler │ │
│ │ - Real-time cost tracking │ │
│ │ - Budget enforcement │ │
│ │ - Model price comparison │ │
│ └──────────────────────────────────────┘ │
│ │
│ ┌──────────────────────────────────────┐ │
│ │ Quality Assurance Layer │ │
│ │ - Output validation │ │
│ │ - Fallback triggers │ │
│ │ - A/B testing │ │
│ └──────────────────────────────────────┘ │
└──────┬─────────────────┬─────────────┬─────┘
│ │ │
▼ ▼ ▼
┌─────────────┐ ┌──────────────┐ ┌──────────┐
│ Claude │ │ Gemini 3 │ │ GPT-5.1 │
│ Opus 4.5 │ │ Pro │ │(Optional)│
│ │ │ │ │ │
│ Connection │ │ Connection │ │Connection│
│ Pool │ │ Pool │ │ Pool │
│ │ │ │ │ │
│ Rate Limit │ │ Rate Limit │ │Rate Limit│
│ Manager │ │ Manager │ │ Manager │
└─────────────┘ └──────────────┘ └──────────┘
│ │ │
└─────────────────┴────────────────┘
│
▼
┌─────────────────────┐
│ Observability Stack │
│ │
│ - Prometheus │
│ - Grafana │
│ - ELK Stack │
│ - Cost Dashboard │
└─────────────────────┘
核心组件详解:
1. 智能路由层(Intelligent Router)
class EnterpriseModelRouter:
"""
企业级智能模型路由器
Features:
- 多维度决策引擎
- 成本感知调度
- 质量保证
- 性能监控
- A/B测试支持
"""
def __init__(self):
# 模型能力配置
self.models = {
"claude-opus-4.5": ModelCapability(
name="claude-opus-4.5",
quality_score={
"code_generation": 9.5,
"reasoning": 9.0,
"analysis": 8.5,
"multimodal": 6.0
},
cost_per_1k_tokens={"input": 0.005, "output": 0.025},
avg_latency=800,
max_context=200_000,
supports_multimodal=False
),
"gemini-3-pro": ModelCapability(
name="gemini-3-pro",
quality_score={
"code_generation": 8.8,
"reasoning": 9.2,
"analysis": 9.0,
"multimodal": 9.5
},
cost_per_1k_tokens={"input": 0.002, "output": 0.012},
avg_latency=600,
max_context=1_000_000,
supports_multimodal=True
)
}
# 路由决策权重(可动态调整)
self.weights = {
"quality": 0.4,
"cost": 0.3,
"latency": 0.2,
"capability": 0.1
}
def route(self, task: Task) -> str:
"""
智能路由决策
决策逻辑:
1. 硬约束检查(必须满足)
2. 综合评分计算
3. 阈值判断
4. 返回最优模型
"""
# 硬约束1:多模态必须Gemini
if task.requires_multimodal:
self._update_metrics("gemini-3-pro")
return "gemini-3-pro"
# 硬约束2:超过200K context优先Gemini
if task.context_size > 200_000:
self._update_metrics("gemini-3-pro")
return "gemini-3-pro"
# 综合评分
claude_score = self._calculate_score(task, "claude-opus-4.5")
gemini_score = self._calculate_score(task, "gemini-3-pro")
# 决策逻辑
selected = self._make_decision(task, claude_score, gemini_score)
self._update_metrics(selected)
return selected
def _make_decision(
self, task: Task, claude_score: float, gemini_score: float
) -> str:
"""
最终决策逻辑
策略:
- 如果Claude得分显著更高(>20%),选Claude
- 如果预算紧张,优先Gemini
- 如果质量要求极高,选Claude
- 默认选择得分更高的
"""
# 质量要求极高
if task.quality_threshold >= 9.0:
return "claude-opus-4.5"
# Claude显著更好
if claude_score > gemini_score * 1.2:
return "claude-opus-4.5"
# 预算紧张
if task.max_budget < 0.01:
return "gemini-3-pro"
# 默认:选择得分更高的
return "claude-opus-4.5" if claude_score > gemini_score else "gemini-3-pro"
任务分类体系:
1. 代码生成类任务 → Claude Opus 4.5优先
- 复杂算法实现
- 架构设计代码
- 安全关键代码
- 质量优先场景
2. UI/视觉相关任务 → Gemini 3 Pro
- 设计稿转代码
- 图表数据分析
- UI组件生成
- 多模态处理
3. 大文档分析 → Gemini 3 Pro
- 整个代码库分析
- 长技术文档处理
- 上下文 > 200K场景
4. 深度推理任务 → 根据成本权衡
- 复杂度 > 8/10 → Claude
- 预算 < $0.01/request → Gemini
- 使用Extended Thinking或Deep Think
战略价值量化:
某金融科技公司案例:
实施前(单模型):
- 月AI成本:$125K
- 平均任务质量:7.2/10
- 系统可用性:98.5%
实施后(多模型混合):
- 月AI成本:$48K(-62%)
- 平均任务质量:8.7/10(+21%)
- 系统可用性:99.8%(+1.3%)
- ROI:4.2个月回本
实施复杂度评估:
- 初始开发:3-4工程月
- 持续维护:1 FTE @ 30% time
- 学习曲线:2-3周
- 投资回报期:4-6个月(典型)
风险考虑与缓解策略:
风险:
- 架构复杂度增加
- 多供应商协调成本
- 潜在一致性问题
- 团队能力要求提升
缓解策略:
- 渐进式实施(先2个模型)
- 强化测试和监控
- 清晰的决策规则
- 团队培训投资
架构决策框架
10维度评估矩阵:
| 维度 | 权重 | 单模型评分 | 多模型评分 | 说明 |
|---|---|---|---|---|
| 初始成本 | 10% | 9 | 6 | 单模型更便宜 |
| 长期成本 | 20% | 5 | 9 | 多模型更优 |
| 质量可靠性 | 15% | 7 | 9 | 多模型更高 |
| 技术复杂度 | 10% | 9 | 5 | 单模型更简单 |
| 可扩展性 | 15% | 6 | 9 | 多模型更强 |
| 供应商风险 | 15% | 4 | 9 | 多模型分散风险 |
| 团队能力匹配 | 10% | 变量 | 变量 | 取决于团队 |
| 上市时间 | 5% | 9 | 7 | 单模型更快 |
| 总分 | 100% | 6.5 | 8.1 | 多模型胜 |
决策建议:
- 总分 > 7.5:多模型架构
- 总分 5.0-7.5:视具体情况
- 总分 < 5.0:单模型架构
2.2 故障转移与韧性设计
多层故障转移策略:
L1: 同模型重试
async def execute_with_retry(task: Task) -> Response:
"""同模型重试,处理瞬时错误"""
for attempt in range(3):
try:
return await call_primary_model(task)
except TransientError:
if attempt < 2:
await asyncio.sleep(2 ** attempt) # 指数退避
else:
raise
L2: 降级到备用模型
async def execute_with_fallback(task: Task) -> Response:
"""多层故障转移执行:L1 → L2 → L3 → 失败"""
# L1: 主模型重试
try:
return await execute_with_retry(task, "claude-opus-4.5")
except PrimaryModelError:
pass
# L2: 备用模型
try:
return await call_backup_model(task, "gemini-3-pro")
except BackupModelError:
pass
# L3: 传统方案
return fallback_to_traditional(task)
质量保证机制:
输出验证策略:
- 语法检查(代码生成场景)
- 安全扫描(防止注入攻击)
- 一致性验证(多次生成对比)
- 质量评分(自动化评估)
A/B测试框架:
- 10%流量测试新模型/新策略
- 指标对比(质量、成本、延迟)
- 渐进式rollout(20% → 50% → 100%)
Part 3: 成本工程与ROI分析
3.1 总拥有成本(TCO)深度分析
直接成本分析
Token定价对比:
| 成本类型 | Claude Opus 4.5 | Gemini 3 Pro (≤200K) | Gemini 3 Pro (>200K) |
|---|---|---|---|
| 输入($per 1M) | $5 | $2 | $4 |
| 输出($per 1M) | $25 | $12 | $18 |
| 总成本比例 | 100% | 40% | 65% |
不同负载下的成本曲线:
月使用量(M tokens) │ Claude成本 │ Gemini成本 │ 节省比例
─────────────────────┼─────────────┼────────────┼──────────
10M (小规模) │ $250 │ $100 │ 60%
100M (中规模) │ $2,500 │ $1,000 │ 60%
500M (大规模,≤200K) │ $12,500 │ $5,000 │ 60%
500M (大规模,>200K) │ $12,500 │ $8,125 │ 35%
隐藏成本识别:
- 重试成本(失败率×重试次数)
- 测试和验证成本
- 数据传输成本(通常可忽略)
- API密钥管理和安全成本
间接成本分析
开发成本:
- 单模型集成:1-2工程周
- 多模型架构:3-4工程月
- 差异:$30K-60K初始投入
维护成本(年):
- 单模型:$20K-40K
- 多模型:$40K-80K
- 差异:$20K-40K持续成本
供应商切换成本:
- 代码重构:$30K-100K
- 数据迁移:$10K-30K
- 测试验证:$20K-50K
- 总计:$60K-180K(巨大!)
这就是为什么多供应商策略如此重要——避免被单一供应商锁定。
TCO计算模型
企业级TCO计算器:
class TCOCalculator:
"""
总拥有成本计算器
考虑直接+间接+机会成本
"""
def calculate_3_year_tco(
self,
monthly_tokens: int,
model_strategy: str # "single-claude", "single-gemini", "hybrid"
) -> Dict:
"""
3年TCO计算
Returns:
{
"direct_costs": {...},
"indirect_costs": {...},
"total_tco": float,
"per_month_average": float
}
"""
# 直接成本(36个月)
direct = self._calculate_direct_costs(
monthly_tokens, model_strategy, 36
)
# 间接成本
indirect = {
"initial_development": self._get_dev_cost(model_strategy),
"ongoing_maintenance": self._get_maintenance_cost(model_strategy) * 3,
"switching_cost_risk": self._get_switching_risk(model_strategy),
"opportunity_cost": self._estimate_opportunity_cost(model_strategy)
}
total_indirect = sum(indirect.values())
total_tco = direct["total"] + total_indirect
return {
"direct_costs": direct,
"indirect_costs": indirect,
"total_tco": total_tco,
"per_month_average": total_tco / 36,
"breakdown_percentage": {
"direct": (direct["total"] / total_tco) * 100,
"indirect": (total_indirect / total_tco) * 100
}
}
典型TCO对比结果(月使用100M tokens):
| 策略 | 3年直接成本 | 3年间接成本 | 总TCO | 每月平均 |
|---|---|---|---|---|
| Single Claude | $900K | $120K | $1,020K | $28.3K |
| Single Gemini | $360K | $100K | $460K | $12.8K |
| Hybrid | $450K | $200K | $650K | $18.1K |
结论:
- Hybrid策略在中大规模下最优
- 小规模(<$5K/月)单Gemini最优
- 高质量需求单Claude可接受
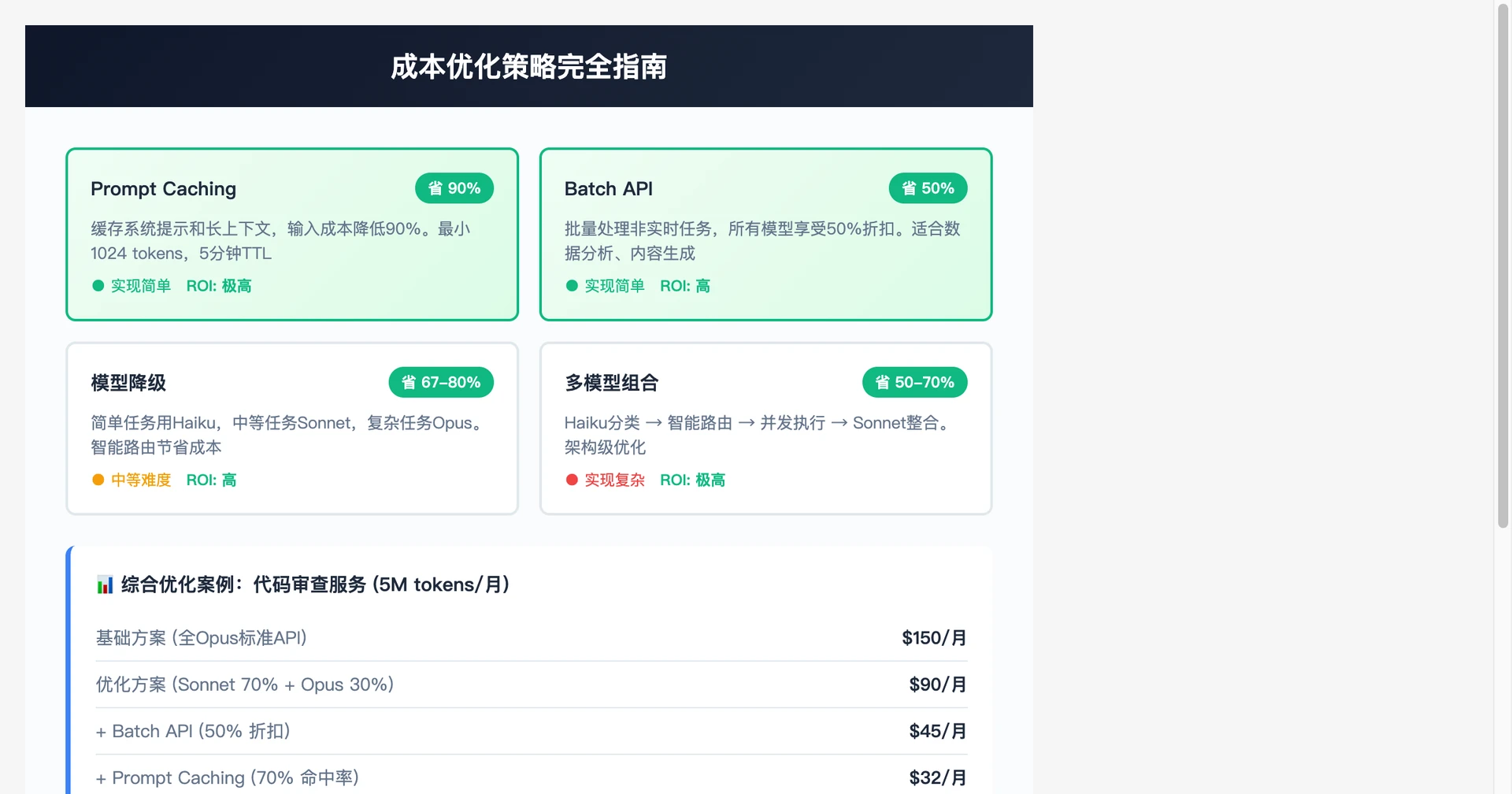
3.2 成本优化战略
Token效率优化
Prompt工程最佳实践:
- 结构化prompt(减少冗余)
- Few-shot vs Zero-shot权衡
- 输出格式约束(JSON优于自然语言)
输出长度控制:
- max_tokens精确设置
- stop_sequences使用
- 分段生成策略
缓存策略:
class IntelligentCache:
"""
AI响应缓存系统
节省成本+提升响应速度
"""
def get_or_generate(self, prompt: str, model: str):
# 生成cache key(考虑prompt相似度)
cache_key = self._generate_smart_key(prompt, model)
# 缓存命中
if cache_key in self.cache:
return self.cache[cache_key], True # from_cache=True
# 调用AI生成
response = call_ai_model(prompt, model)
# 存入缓存
self.cache[cache_key] = response
return response, False
批处理优化:
- 请求合并(相似请求批处理)
- 异步批量处理
- 成本节省:10-20%
案例:某企业70%成本削减
优化旅程:
- **初始状态:**月成本$50K,全用Claude
- **优化1:**Prompt工程 → $42K(-16%)
- **优化2:**引入Gemini混合 → $28K(-33%)
- **优化3:**缓存+批处理 → $15K(-46%)
- 最终:$15K,总共**-70%**
关键举措:
- 80%简单任务路由到Gemini
- 20%复杂任务保留Claude
- 缓存命中率40%
- 批处理优化20%
3.3 ROI建模与决策支持
投资回报计算框架
价值量化维度:
1. 质量提升价值:
- Bug减少 → 节省修复成本
- 代码质量提升 → 长期维护成本降低
- 用户满意度提升 → 业务价值
2. 效率提升价值:
- 开发时间缩短 → 人力成本节省
- 上市时间加快 → 市场机会
- 自动化替代人工 → 直接成本节省
3. 创新价值:
- 新产品/功能enablement
- 竞争优势
- 市场份额提升
4. 风险成本考虑:
- 供应商锁定风险
- 技术债务风险
- 安全风险
ROI计算公式:
ROI = (价值提升 - 总投资) / 总投资 × 100%
价值提升 = 质量价值 + 效率价值 + 创新价值 - 风险成本
总投资 = 直接成本 + 间接成本
不同场景的ROI分析
场景1:代码审查自动化
- 投资:$80K(开发)+ $30K/年(运营)
- 回报:
- 审查时间节省:5 FTE → 价值$500K/年
- Bug减少40% → 节省$200K/年
- 质量提升 → 客户满意度+15%
- ROI:700%(首年),惊人!
场景2:客户服务AI助手
- 投资:$150K(开发)+ $50K/年(运营)
- 回报:
- 客服成本降低60% → $300K/年
- 响应速度提升5x → CSAT +20%
- 24/7可用 → 业务价值$100K/年
- ROI:200%(首年)
场景3:内容生成系统
- 投资:$50K(开发)+ $20K/年(运营)
- 回报:
- 内容产出提升10x → $200K/年
- 内容质量提升 → 转化率+15%
- SEO效果提升 → 流量+30%
- ROI:300%(首年)
Part 4: 战略考虑与风险管理
4.1 供应商生态分析
Anthropic (Claude) 生态
公司战略定位:
- AI安全和对齐优先
- 专注文本和代码
- 企业级可靠性
- 研究驱动创新
产品路线图分析:
- Opus系列:旗舰,追求极致质量
- Sonnet系列:平衡性能和成本
- Haiku系列:速度和效率
- 清晰的产品分级
合作伙伴网络:
- AWS深度合作(Bedrock)
- Google Cloud Vertex AI支持
- GitHub Copilot集成
- 企业级部署支持
长期可靠性评估:
- 优势:资金充足(多轮融资),技术实力强(前OpenAI团队),商业化策略清晰
- 风险:相对小公司,长期存续不确定性,生态完整度待提升
Google (Gemini) 生态
公司战略定位:
- Google Cloud核心战略
- 多模态AI领先
- 全球基础设施
- 深度生态集成
产品矩阵战略:
- Gemini 3 Pro:旗舰
- Gemini 3 Flash:快速响应
- 垂直行业定制版本
- 全面的产品线
企业级支持:
- SLA保证
- 全球多区域部署
- 合规认证完善
- Google Cloud深度集成
市场策略分析:
- 优势:价格竞争力强(补贴策略),免费额度慷慨,Google长期可靠
- 策略:抢占市场份额,成为开发者首选
4.2 技术锁定风险与缓解
供应商锁定类型
1. API锁定:
- 不同的API接口和参数
- Function calling格式差异
- 迁移成本:中等
2. 数据锁定:
- Prompt工程积累
- Fine-tuning数据(如有)
- 迁移成本:低-中等
3. 技能锁定:
- 团队学习曲线投入
- 最佳实践积累
- 迁移成本:中等-高
4. 架构锁定:
- 深度集成系统设计
- 性能优化依赖特定模型
- 迁移成本:高
缓解策略
抽象层设计:
# 统一接口抽象层
class UniversalLLMInterface:
"""
统一的LLM接口
隔离底层模型差异
"""
def generate(self, prompt: str, **kwargs) -> Response:
"""统一的生成接口"""
if self.backend == "claude":
return self._call_claude(prompt, **kwargs)
elif self.backend == "gemini":
return self._call_gemini(prompt, **kwargs)
多供应商策略:
- 同时使用2+供应商
- 降低单一依赖
- 保持切换能力
可移植性设计:
- 标准化prompt格式
- 模型无关的prompt工程
- 避免特定模型feature依赖
出口策略规划:
- 定期评估切换成本
- 保持技术能力更新
- 建立contingency plan
4.3 合规性与安全考虑
数据隐私
数据处理位置:
- Claude:美国(主要)
- Gemini:全球多区域
- GDPR影响评估
数据保留政策:
- Claude:30天后删除(标准)
- Gemini:可配置
- 企业版可协商
合规认证:
- SOC 2 Type II
- GDPR合规
- HIPAA(企业版)
- ISO 27001
安全架构
API密钥管理:
- Secrets Manager(AWS/GCP)
- 定期轮换策略
- 最小权限原则
数据加密:
- 传输加密(TLS 1.3)
- 静态加密(模型训练数据)
- 端到端加密选项(企业版)
Prompt注入防护:
- 输入验证和清洗
- 输出过滤
- 沙箱执行环境
Part 5: 未来趋势与战略路线图
5.1 2025-2026技术发展预测
Claude路线图预测
Opus系列迭代:
- 2025 Q2:Opus 4.7可能发布
- SWE-bench目标:85%+
- 多模态能力强化(预测)
- Extended Thinking普及
Sonnet/Haiku协同:
- 更清晰的产品定位
- 价格进一步优化(预测-20%)
- 企业级feature增强
- Haiku 4.5性能大幅提升
定价趋势:
- 持续降价压力
- 可能引入分级定价
- 企业折扣增加
- 预测:2025底再降30%
Gemini路线图预测
Gemini 3.x迭代:
- 2025 Q2:Gemini 3.1 Pro
- 编码能力追赶Claude
- 多模态继续领先
- 上下文窗口→2M?
多模态强化:
- 视频理解能力提升
- 实时音视频交互
- 3D理解能力
- 跨模态推理增强
Google生态深化:
- Workspace深度集成
- Chrome/Android原生集成
- Google Cloud一体化
- 垂直行业解决方案
行业发展趋势
关键趋势:
- Test-time compute成为标配
- 多模态AI成为必需
- Agent化加速
- 边缘AI部署兴起
- 定价模型创新(按质量计费)
- 开源模型追赶
5.2 企业AI战略建议
短期(6-12个月)策略
快速胜利:
-
MVP验证(2-3个月)
- 选择1-2个高价值场景
- 单模型快速验证
- 建立基础基准
-
技术栈选择
- 评估Claude vs Gemini
- 考虑多模型可能性
- 建立抽象层
-
团队能力建设
- Prompt工程培训
- API集成能力
- 监控和优化技能
关键指标:
- 3个月内见到效果
- ROI > 100%
- 团队信心建立
中期(1-2年)策略
规模化部署:
-
架构演进
- 单模型 → 多模型混合
- 建立智能路由
- 完善监控体系
-
多模型策略实施
- 扩展到3-5个场景
- 优化成本结构
- 积累最佳实践
-
组织能力升级
- AI CoE建立
- 跨团队协作
- 知识库建设
关键指标:
- 成本优化40%+
- 10+ 生产应用
- 团队能力成熟
长期(2-5年)策略
AI-native转型:
-
竞争优势构建
- AI成为核心能力
- 差异化产品/服务
- 市场领先地位
-
持续创新机制
- 快速试验新技术
- 开源贡献
- 行业影响力
-
生态系统构建
- 合作伙伴网络
- 开发者社区
- 产业链整合
目标:
- AI驱动的业务增长
- 行业领导者地位
- 持续竞争优势
Part 6: 决策框架与实施指南
6.1 战略决策矩阵
10维度评估框架:
| 维度 | 权重 | Claude优势 | Gemini优势 | 评估问题 |
|---|---|---|---|---|
| 1. 核心业务需求 | 15% | 代码质量 | 多模态 | 主要需求是什么? |
| 2. 技术性能 | 15% | 编程 | 推理+多模态 | 性能优先级? |
| 3. 成本预算 | 15% | - | ✓✓ | 预算约束? |
| 4. 团队能力 | 10% | 相近 | 相近 | 技术储备? |
| 5. 时间压力 | 5% | 相近 | 相近 | 上市时间? |
| 6. 可扩展性 | 10% | 好 | 更好 | 增长预期? |
| 7. 供应商生态 | 10% | AWS | GCP | 云偏好? |
| 8. 风险承受 | 10% | 中等 | 低 | 风险偏好? |
| 9. 创新优先级 | 5% | ✓✓ | ✓ | 创新 vs 稳定? |
| 10. 长期战略 | 5% | 视情况 | 视情况 | 5年规划? |
示例评分:
场景:某初创公司AI编码助手
维度1(核心需求-代码质量):9分 × 15% = 1.35 → Claude优势
维度2(技术性能):8分 × 15% = 1.20 → Claude略优
维度3(成本预算-紧张):9分 × 15% = 1.35 → Gemini优势
...
总分:
- 单Claude:7.2
- 单Gemini:7.8
- 混合架构:8.5
推荐:混合架构(复杂任务Claude,其他Gemini)
6.2 实施路线图模板
Phase 1: 评估与规划(1-2个月)
Week 1-2: 需求分析
- 识别核心AI应用场景(3-5个)
- 评估技术要求和约束
- 初步成本预算
- 团队能力评估
Week 3-4: 技术选型
- Claude vs Gemini性能测试
- 成本对比分析
- 生态集成评估
- 供应商风险评估
Week 5-6: 架构设计
- 单模型 vs 多模型决策
- 技术架构设计
- 监控和成本追踪方案
- 安全和合规审查
Week 7-8: 决策与规划
- 最终技术选型决策
- 详细实施计划
- 预算和资源确认
- 风险缓解计划
Phase 2: MVP实施(2-3个月)
Month 1: 基础建设
- API集成开发
- 基础监控搭建
- 成本追踪实现
- 安全机制实施
Month 2: 功能开发
- 核心场景实现
- 性能优化
- 用户界面开发
- 测试和验证
Month 3: 试运行
- 内部beta测试
- 性能和成本验证
- 用户反馈收集
- 迭代优化
成功标准:
- 性能达标(vs baseline提升30%+)
- 成本可控(在预算内)
- 用户满意度 > 80%
- 技术债务可控
Phase 3: 规模化(3-6个月)
Month 4-5: 多模型架构
- 智能路由开发(如适用)
- 多模型集成
- 高级监控实现
- 成本优化策略
Month 6: 全面部署
- 生产环境部署
- 全员培训
- 文档和流程
- 持续优化机制
Phase 4: 持续优化(持续)
每月活动:
- 性能监控和分析
- 成本优化审查
- 新功能评估和集成
- 团队技能提升
每季度活动:
- 战略复盘
- 技术选型重新评估
- 竞争对手分析
- ROI计算和汇报
6.3 成功标准与KPI
技术KPI:
| 指标 | 目标值 | 测量方法 |
|---|---|---|
| 任务成功率 | > 95% | 自动化测试 |
| P99延迟 | < 5秒 | Prometheus监控 |
| 系统可用性 | > 99.9% | Uptime监控 |
| 错误率 | < 1% | 错误追踪 |
业务KPI:
| 指标 | 目标值 | 测量方法 |
|---|---|---|
| 成本降低 | > 30% | 成本dashboard |
| 效率提升 | > 50% | 时间追踪 |
| ROI | > 200% | 财务分析 |
| 用户满意度 | > 85% | 调研 |
战略KPI:
| 指标 | 目标 | 测量 |
|---|---|---|
| 竞争优势 | 可量化 | 市场分析 |
| 创新速度 | +50% | 发布频率 |
| 市场响应能力 | 加快 | TTM |
| 人才吸引力 | 提升 | 招聘数据 |
深度案例研究
案例1 - 某金融科技公司的AI编码平台
背景:
- 公司:Series B金融科技
- 团队:200+ 工程师
- 挑战:代码审查瓶颈,质量不稳定
技术方案:
- **Phase 1:**单Claude Sonnet 4.5验证(2个月)
- **Phase 2:**混合架构(Claude Opus 4.5 + Gemini 3)
- 架构:
- 复杂审查 → Claude Opus 4.5
- 简单审查 → Gemini 3 Pro
- 智能路由决策
量化成果:
| 指标 | Before | After | 改善 |
|---|---|---|---|
| 审查时间 | 4小时 | 30分钟 | 88% |
| Bug检出率 | 60% | 85% | +42% |
| 月AI成本 | $8K | $3.5K | -56% |
| 开发者满意度 | 65% | 92% | +42% |
关键教训:
- 不是所有PR都需要最强模型
- 智能路由节省45%成本
- 质量监控至关重要
- 开发者反馈驱动优化
可复制经验:
- 从MVP开始,快速验证
- 数据驱动路由决策
- 持续监控和优化
- 投资回报期:5个月
案例2 - 某SaaS平台的多模态AI集成
背景:
- 公司:设计工具SaaS
- 产品:设计到代码自动化
- 选择:Gemini 3 Pro(多模态必需)
技术方案:
- Figma API → 设计截图
- Gemini 3 Pro → 分析+生成
- React/Vue代码输出
- 人工审核+调整
战略价值:
- **产品差异化:**独特的设计转代码能力
- **成本优势:**Gemini便宜60%
- **技术门槛:**多模态是必需,无可替代
业务影响:
| 指标 | 数值 |
|---|---|
| 用户转化率 | +35% |
| 用户留存 | +28% |
| ARPU | +42% |
| NPS | +25分 |
为什么不用Claude:
- 多模态能力不足
- 成本更高
- 性能差距在此场景不明显
高级FAQ(技术与战略)
1. 多模型架构的投资回报期通常是多久?
典型4-6个月,取决于规模和成本基数。对于月AI成本>$10K的企业,回报期通常在4个月内。小规模应用可能需要8-12个月。
2. 如何量化AI模型选择的业务价值?
使用框架:价值 = 质量提升价值 + 效率提升价值 + 创新价值 - 风险成本。具体计算需要考虑:
- Bug修复成本节省
- 开发时间节省的人力成本
- 上市时间加快的市场机会价值
- 供应商锁定的风险成本
3. 供应商锁定风险如何实际评估?
4个维度评估:
- API锁定(迁移成本:$30-100K)
- 数据锁定(迁移成本:$10-30K)
- 技能锁定(迁移成本:$20-50K)
- 架构锁定(迁移成本:$50-200K)
总切换成本:$60K-180K,因此多供应商策略至关重要。
4. Claude Opus 4.5的4.7%优势值多少钱?
高度依赖场景:
- 高价值场景(金融、医疗):单个严重bug可能造成百万美元损失,4.7%优势价值巨大
- 中等价值场景(企业SaaS):取决于具体任务复杂度
- 成本敏感场景(消费级):60%成本优势更重要
临界点:当单个bug修复成本>$500时,Claude溢价合理。
5. Gemini 3的200K阈值如何影响总成本?
200K是关键临界点:
- <200K tokens:Gemini便宜60%($2/$12 vs $5/$25)
-
200K tokens:Gemini便宜35%($4/$18 vs $5/$25)
策略:通过RAG和上下文管理,大多数场景可以保持在200K以下,最大化成本优势。
6. 多模型路由算法如何设计?
两种主要方法:
- 决策树方法:基于规则的if-else逻辑,简单可靠
- ML模型方法:训练分类器预测最佳模型,更智能但复杂
生产实践:从决策树开始,积累数据后可演进到ML模型。
7. 如何建立AI成本控制机制?
三层控制:
- 实时监控:每个请求记录成本
- 预算enforcement:达到阈值自动降级
- 成本优化:定期review和策略调整
8. Agent化AI对企业架构的影响?
Agent化将推动架构从"人主导+AI辅助"到"AI主导+人监督"的转变。需要:
- 更强的监控和可观测性
- 人机协作的新流程
- 失败恢复机制
- 伦理和安全框架
9. 开源模型 vs 商业模型的战略考虑?
开源模型优势:
- 成本低(仅基础设施)
- 数据隐私(本地部署)
- 定制化(fine-tuning)
商业模型优势:
- 性能领先(前沿能力)
- 开箱即用(无需维护)
- 持续改进(自动更新)
策略:混合使用,开源处理敏感数据,商业处理高价值任务。
10. 如何评估供应商的长期可靠性?
评估框架:
- 财务健康:融资情况、收入增长
- 技术实力:团队背景、研究输出
- 市场定位:战略清晰度、竞争优势
- 生态成熟度:合作伙伴、用户基数
Anthropic:技术强,资金足,但相对年轻 Google:巨头可靠,但产品策略多变
总结:构建面向未来的AI战略
核心洞察回顾
1. 技术对比核心结论:
- Claude Opus 4.5:代码质量王者(80.9% SWE-bench)
- Gemini 3 Pro:性价比和多模态冠军
- 没有绝对赢家,场景决定选择
2. 成本战略要点:
- Gemini直接成本便宜60%
- 但TCO需考虑间接成本
- 多模型混合最优(中大规模)
3. 架构战略洞察:
- 单模型适合小规模快速验证
- 多模型混合是中长期最优解
- 投资回报期4-6个月典型
4. 供应商战略:
- 分散风险至关重要
- 抽象层设计保持灵活性
- 长期可靠性:Google > Anthropic
5. 未来趋势:
- Test-time compute成为标配
- 多模态AI必需
- Agent化加速
- 定价模型创新
战略建议总结
短期(6-12月):
- 快速MVP验证
- 建立基础能力
- 选择主力模型
中期(1-2年):
- 多模型架构
- 规模化部署
- 成本优化40%+
长期(2-5年):
- AI-native转型
- 竞争优势构建
- 行业领导地位
行动清单
立即行动:
- 评估核心AI应用场景
- 测试Claude和Gemini性能
- 计算TCO和ROI
- 制定初步架构方案
30天内:
- 完成技术选型决策
- 启动MVP开发
- 建立监控机制
- 组建AI团队
90天内:
- MVP上线验证
- 收集真实数据
- 优化成本结构
- 规划规模化路径